Gen AI Developer Week 2 — Day 5
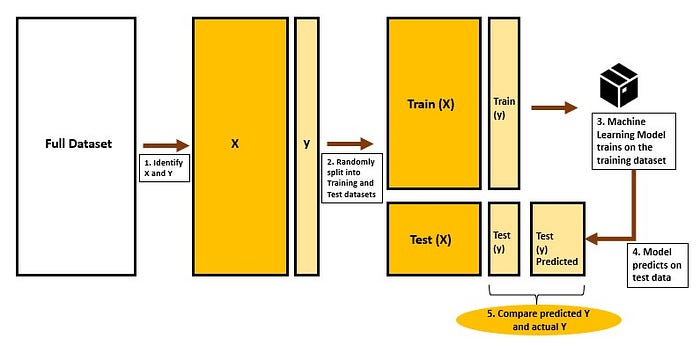
The machine learning workflow is a structured process that ensures models are both trained effectively and evaluated accurately. A key step is the train-test split, where the dataset is divided into training and testing sets to prevent overfitting and assess model performance on unseen data. Coupled with techniques like cross-validation and metrics such as accuracy, precision, and recall, model evaluation provides critical insights into how well a model generalizes. This article dives into these essential steps, forming the backbone of a robust machine learning pipeline.
Let’s get started with Practical Examples
# Train Test Split on Iris Dataset
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_iris
import pandas as pd
iris = load_iris()
df_iris = pd.DataFrame(data=iris.data, columns=iris.feature_names)
df_iris['target'] = iris.target
X = df_iris.drop('target', axis=1)
y = df_iris['target']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
print("Training set size:", X_train.shape)
print("Testing set size:", X_test.shape)
# k-Nearest Neighbors Classification - On Iris Dataset
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import classification_report, confusion_matrix
# Train k-NN model
knn = KNeighborsClassifier(n_neighbors=3)
knn.fit(X_train, y_train)
# Predictions
y_pred_knn = knn.predict(X_test)
# Evaluation
print("Classification Report:")
print(classification_report(y_test, y_pred_knn))
print("Confusion Matrix:")
print(confusion_matrix(y_test, y_pred_knn))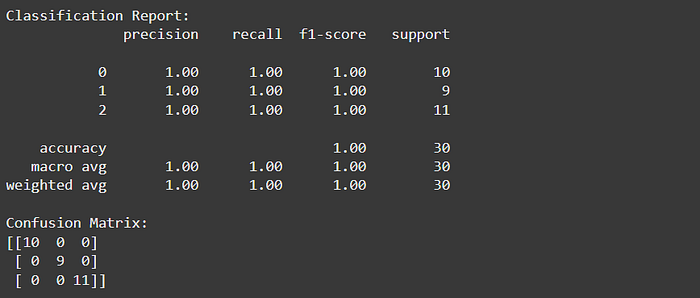
What is k-NN ?
Imagine you have a group of friends with different hobbies. You want to know what hobbies a new friend might like. kNN is like asking your k closest friends what their hobbies are, and then assuming your new friend will like the most common hobbies among those k friends.
In machine learning:
Data points: Your friends and their hobbies.
New data point: Your new friend.
k: The number of closest friends you ask.
Classification: Predicting the new friend’s hobbies based on their closest friends’ hobbies.
Deliverables for the day:
- Training and testing data summary (e.g., size of splits).
- Classification report for k-NN (
Accuracy,Precision,Recall,F1-Score)
Happy Learning!😊.. For any questions or support, feel free to message me on LinkedIn.