Gen AI Developer Week 2 — Day 3

Data is the fuel for any machine learning model, but very rarely does raw data lend itself to analysis. Data preprocessing is the all-important first step to ensure that your data is clean and consistent for the purpose of getting the most important insights from it. From handling missing values to scaling features, preprocessing modifies messy datasets into structured inputs that models understand. This article is a continuation of my journey through Generative AI Developer Week that introduces the key techniques and importance of data preprocessing in the machine-learning pipeline.
Simulate Missing Data
# Handelling Missing Data in Datasets
import pandas as pd
import numpy as np
data = {
'Age' : [25, 30, np.nan, 40, 50],
'Salary' : [50000, 60000, 70000, np.nan, 90000],
'Country' : ['USA', 'Canada', 'Mexico', 'USA', np.nan]
}
df = pd.DataFrame(data)
print("Dataset with missing values:\n", df)
Handle Missing Values — Drop rows/columns
df_dropped = df.dropna() # Function used to remove or drop the missing values
print("\nDataset after dropping missing values:\n", df_dropped)
Handle Missing Values — Fill missing values with a strategy (e.g., mean, median, or mode)
# Statergy based filling the missed values
df['Age'] = df['Age'].fillna(df['Age'].mean())
df['Salary'] = df['Salary'].fillna(df['Salary'].median())
df['Country'] = df['Country'].fillna(df['Country'].mode()[0])
print("\nDataset after filling missing values:\n", df)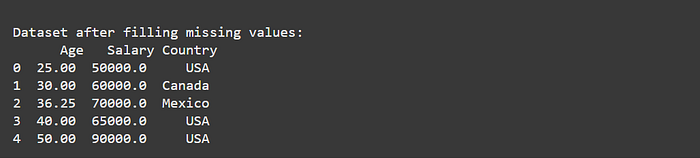
Encoding Categorical Variables — One-Hot Encoding
Convert categorical features into numerical format for ML models.
# Encoding Categorical Variables
df_encoded = pd.get_dummies(df, columns=['Country'], drop_first=True)
print("\nOne-hot encoded dataset:\n", df_encoded)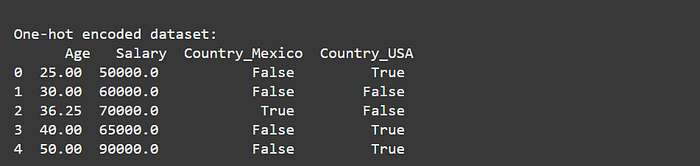
Feature Scaling Standardization (Z-Score Normalization)
Ensure numerical features are on the same scale to avoid bias in ML models.
# Feature Scaling
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
# Standard Scaler
# StandardScaler is a data preprocessing technique that scales
# numerical features to have a mean of 0 and a standard deviation of 1.
df_encoded[['Age', 'Salary']] = scaler.fit_transform(df_encoded[['Age', 'Salary']])
print("\nDataset after feature scaling:\n", df_encoded)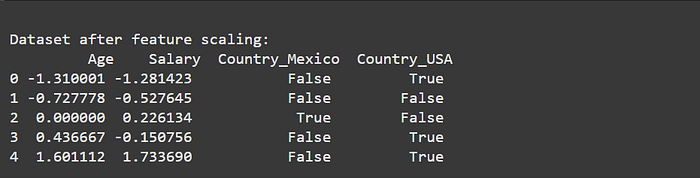
Practices Tasks
Task 1 — Create a new dataset with at least 3 numerical and 2 categorical columns. Introduce missing values and preprocess the dataset.
Task 2 — Compare the effect of standardization and normalization (Min-Max scaling) on a dataset using MinMaxScaler from Scikit-learn.
Task 3 — Use the preprocessed dataset to train a Linear Regression model (revisit Day 2).
Example of Task 3 — Model Trained on the Existing Dataset discussed above for this tutorial.
import pandas as pd
import numpy as np
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, r2_score
X = df_encoded.drop('Salary', axis=1)
y = df_encoded['Salary']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
model = LinearRegression()
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
print("Coefficients:", model.coef_)
print("Intercept:", model.intercept_)
print("Mean Squared Error:", mse)
print("R-squared:", r2)
Deliverables for the day:
A clean dataset with missing values handled and categorical features encoded.
Standardized and/or normalized numerical features.
Happy Learning!😊.. For any questions or support, feel free to message me on LinkedIn.